考完还得记的数学知识(
高数
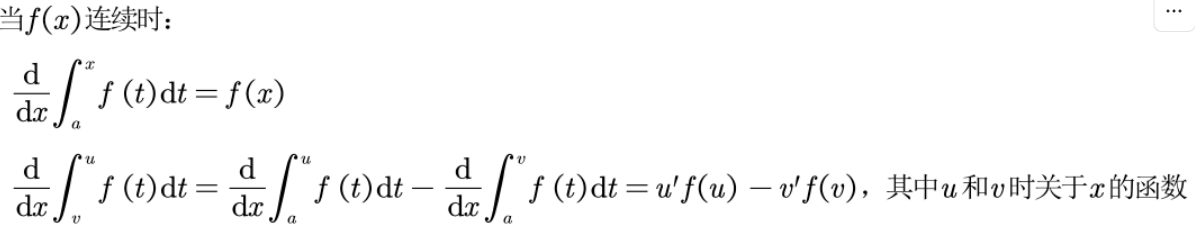
线代
基础
[《线性代数》总复习要点、公式、重要结论与重点释疑_线性代数知识点总结及公式-CSDN博客](https://blog.csdn.net/love502504065/article/details/103983097#:~:text=本文提供《线性代数》总复习要点、公式、重要结论及释疑,配套同济版教材,由武汉大学黄正华老师整理,适合学习交流。 本文内容 配套教材:同济版:线性代数 (第五版),,来源于 武汉大学数学与统计学院信息与计算科学系黄正华 老师个人网页,分享仅供学习参考交流,相关课程更多内容通过黄老师个人网站获取,网址: http%3A%2F%2Faff.whu.edu.cn%2Fhuangzh)
求逆矩阵:矩阵逆的三种求法-CSDN博客
矩阵论
矩阵求导的本质与分子布局、分母布局的本质(矩阵求导——本质篇) - 知乎用户5heCTT的文章 - 知乎
https://zhuanlan.zhihu.com/p/263777564
矩阵求导公式的数学推导(矩阵求导——基础篇) - 知乎用户5heCTT的文章 - 知乎
https://zhuanlan.zhihu.com/p/273729929
矩阵求导公式的数学推导(矩阵求导——进阶篇) - 知乎用户5heCTT的文章 - 知乎
https://zhuanlan.zhihu.com/p/288541909
小知识点
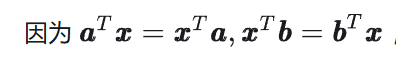
因为这个计算结果是1x1的实数,转置不变
大知识点
对向量求导是什么意思
其实是在问:“由于我有好几个输入变量,我该如何同时调整它们,才能让结果发生我想要的变化?”
1. 直观理解:控制面板的比喻
想象你在操作一个复杂的机器(比如调音台或者飞行模拟器)。
- 标量求导(普通求导):
- 你的控制面板上只有一个旋钮 $x$。
- 你的目标是让音量 $y$ 变大。
- 求导 $\frac{dy}{dx}$ 就是在问:“如果我把这个旋钮往右拧一点点,音量会变大还是变小?”
- 向量求导(对向量求导):
- 现在你的控制面板上有 100 个旋钮($x_1, x_2, \dots, x_{100}$)。我们把这 100 个旋钮的状态统称为向量 $\mathbf{x}$。
- 你的目标还是让音量 $y$ 变大。
- 对向量求导 $\frac{\partial y}{\partial \mathbf{x}}$ 就是在问:“为了让音量变大得最快,这一瞬间,我应该如何同时调整这 100 个旋钮?”
- 答案是一个向量(比如 $[+0.1, -0.5, +2, \dots]$)。这告诉你:第 1 个旋钮往右拧一点,第 2 个往左拧多点,第 3 个往右猛拧……
结论: 对向量求导,结果是一个清单(List),清单上的每一个数字告诉你要怎么调整对应的那个变量。
2. 几何理解:蒙眼爬山
在机器学习中,我们常说“梯度下降”。这里的**梯度(Gradient)**其实就是“对向量求导”的结果。
- 场景: 你站在一座山上(由函数 $f(\mathbf{x})$ 定义形状)。
- 位置 $\mathbf{x}$: 你的坐标是 $(x_1, x_2)$,这是一个向量。
- 高度 $y$: 你所在位置的海拔高度。
- 求导结果 $\nabla f(\mathbf{x})$: 这是一个箭头(向量)。
- 它指向最陡峭的上坡方向。
- 它的长度代表坡度有多陡。
如果你想下山(最小化损失函数),你就沿着这个向量的反方向走一步。这就是 $w_{new} = w - \eta \cdot \text{导数}$ 的物理意义。
3. 数学实战:手动算一次
让我们看一个最简单的例子,把抽象变具体。
假设有一个函数 $f(\mathbf{x}) = x_1^2 + 3x_2$。
这里向量 $\mathbf{x} = \begin{bmatrix} x_1 \ x_2 \end{bmatrix}$。
我们要计算 $\frac{\partial f}{\partial \mathbf{x}}$。
步骤 1:拆解(零售)
- 对 $x_1$ 求偏导:$2x_1$
- 对 $x_2$ 求偏导:$3$
步骤 2:打包(批发)
把它们按照 $\mathbf{x}$ 的形状拼起来:
$$\frac{\partial f}{\partial \mathbf{x}} = \begin{bmatrix} 2x_1 \ 3 \end{bmatrix}$$
这意味着什么?
假设现在的输入是 $\mathbf{x} = [1, 5]^T$。
代入导数公式得到结果 $[2, 3]^T$。
这就告诉你:
- $x_1$ 对结果的影响系数是 2(改变 $x_1$,结果变 2 倍量)。
- $x_2$ 对结果的影响系数是 3(改变 $x_2$,结果变 3 倍量)。
- 如果你想让函数值增加最快,你应该把 $x_2$ 增加的比 $x_1$ 多一点(因为 3 > 2)。
总结
对向量求导 = 灵敏度分析的集合
它不是什么新数学,只是把我们对每个变量做的灵敏度分析(偏导数),整齐地排列成一个列向量,方便计算机一次性读取和更新。
对矩阵求导又是什么意思
对矩阵求导就是给你一张Excel 表格(或者一个二维网格),对应位置告诉你每个元素该怎么调。
1. 直观理解:Excel 表格的比喻
想象你的机器学习**模型是一个巨大的 Excel 表格(矩阵 $W$),**里面填满了数字。
最终的计算结果(Loss)是一个单独的数字(比如误差值)。
对矩阵 $W$ 求导 ($\frac{\partial L}{\partial W}$) 的意思就是:
为了让那个最终的误差值 $L$ 变小,我需要同时调整表格里的每一个格子。
- $(1,1)$ 这个格子的数字应该加一点还是减一点?
- $(3,5)$ 这个格子的数字应该动多少?
结果: 你会得到一个形状完全一样的“影子表格”(梯度矩阵)。
这个“影子表格”里的每一个数字,都代表了对应原位置数字的灵敏度。
2. 数学定义:二维的打包
假设矩阵 $W$ 是一个 $m \times n$ 的矩阵:
$$W = \begin{bmatrix} w_{11} & \dots & w_{1n} \ \vdots & \ddots & \vdots \ w_{m1} & \dots & w_{mn} \end{bmatrix}$$
我们对标量 $L$ 求关于 $W$ 的导数,结果也是一个 $m \times n$ 的矩阵:(拿整体L分别对每个位置的wij求偏导)
$$\frac{\partial L}{\partial W} = \begin{bmatrix} \frac{\partial L}{\partial w_{11}} & \dots & \frac{\partial L}{\partial w_{1n}} \ \vdots & \ddots & \vdots \ \frac{\partial L}{\partial w_{m1}} & \dots & \frac{\partial L}{\partial w_{mn}} \end{bmatrix}$$
核心原则: 形状不变**。$W$ 长什么样,它的导数(梯度)就长什么样。这样你才能把它们直接相减(更新参数):**
$$W_{new} = W_{old} - \eta \cdot \frac{\partial L}{\partial W}$$
3. 为什么机器学习需要它?
在神经网络(深度学习)中,层与层之间的连接通常不是几根线,而是全连接。
比如输入层有 100 个神经元,隐藏层有 50 个神经元,它们之间的连接权重就是一个 $100 \times 50$ 的矩阵。
训练神经网络时,我们需要一次性更新这 5000 个权重。如果我们不会“对矩阵求导”,我们就得写 5000 次标量求导公式——那简直是灾难。学会了矩阵求导,一行代码就搞定了。
对矩阵求导,就是计算一个同形状的梯度矩阵,告诉我们需要如何调整矩阵里的每一个元素来降低误差。
矩阵求导的基本原则
本质上还是我们熟悉的单变量微积分,只是我们将一堆导数打包成了一个矩阵或向量。
我为你总结了矩阵求导的 三大核心原则 和 一套生存指南:
1. 核心原则一:维度相容原则 (The Dimension Compatibility Rule)
这是最重要的原则,也是我们之前讨论“转置”问题的根源。
- 原则: 导数的形状(Shape)必须与变量的形状在逻辑上“兼容”。
- 怎么用: 比如标量 $L$ 对向量 $x$($n \times 1$)求导。
- 如果你想要在这个梯度上做加减法(如 $x_{new} = x - \text{gradient}$),那么梯度的形状必须也是 $n \times 1$。
- 这就是为什么我们会看到 $A^T$ 出现——为了把维度“扭”回来,让它能和 $x$ 进行运算。
2. 核心原则二:布局决定形式 (Layout Matters)
这就像是语言的“方言”。同一个数学事实,用不同的“方言”写出来,转置的位置会不同。
- 分母布局 (Denominator Layout)(机器学习常用):
- 定义: 标量对向量求导,结果是列向量(跟分母 $x$ 长得一样)。
- 例子: 若 $y = A x$,则 $\frac{\partial y}{\partial x} = A^T$。
- 优点: 梯度方向直接对应参数更新方向。
- 分子布局 (Numerator Layout)(数学教材常用):
- 定义: 标量对向量求导,结果是行向量(跟分子转置后一样)。
- 例子: 若 $y = A x$,则 $\frac{\partial y}{\partial x} = A$。
- 优点: 形式上更符合雅可比矩阵定义。
学习建议: 不用死记硬背。如果你在看论文或推导时发现维度对不上(比如本该相乘的矩阵乘不了),试着加个转置 ($T$) 通常就对了。
3. 核心原则三:标量化思维 (Scalarization)
当你面对复杂的矩阵求导不知所措时,可以退回到最基础的方法:
- 拆开: 把矩阵运算写成一个个标量的求和形式($\sum$)。
- 求导: 对其中某一个元素 $x_k$ 求偏导。
- 重组: 把所有偏导的结果重新拼回成矩阵形式。
eg.
这里的 $x$ 是自变量(Variable),而 $x^T$ 只是对自变量做了一个操作(Operation)。
就像我们在中学学函数 $f(t) = t^2$ 时,我们是求 $\frac{df}{dt}$(对 $t$ 求导),而不是求 $\frac{df}{dt^2}$。虽然公式里写的是 $t^2$,但变量本质是 $t$。
为什么结果是 $A$?(推导逻辑)
让我们用“拆解法”来看一下,为什么 $f(x) = x^T A$ 对 $x$ 求导的结果是 $A$(在分母布局下):
- 设维度:
- $x$ 是 $n \times 1$ 的列向量。
- $A$ 是 $n \times m$ 的矩阵。
- $f(x) = x^T A$ 的结果是一个 $1 \times m$ 的行向量。
- 看单个元素:
- 设 $f(x)$ 的第 $j$ 个元素是 $y_j$。
- 根据矩阵乘法,$y_j$ 等于 $x$ 的所有元素与 $A$ 的第 $j$ 列对应相乘之和。
- 即:$y_j = x_1 A_{1j} + x_2 A_{2j} + \dots + x_n A_{nj}$。
- 求偏导:
- 如果我们对 $x$ 中的某一个分量 $x_i$ 求导:$\frac{\partial y_j}{\partial x_i} = A_{ij}$。
- 你会发现,导数就是矩阵 $A$ 中的元素。
- 拼回去:
- 当我们把所有这些偏导数按照分母布局(让导数维度兼容 $x$ 的列向量形式)拼回去时,结果正好就是矩阵 $A$。
机器学习常用“作弊表” (Common Formulas)
在机器学习中(假设使用分母布局),你 90% 的时间只会用到下面这几个公式。一定要记住它们!
假设 $x$ 是向量,$A$ 是与 $x$ 无关的矩阵:
| 函数形式 | 导数 (分母布局) | 直观记忆法 |
|---|---|---|
| $f(x) = A x$ | $A^T$ | 类似于 $ax$ 的导数是 $a$,但在分母布局下要转置 |
| $f(x) = x^T A$ | $A$ | 类似于 $ax$ 的导数是 $a$ |
| $f(x) = x^T x$ | $2x$ | 类似于 $x^2$ 的导数是 $2x$ |
| $f(x) = x^T A x$ | $(A + A^T)x$ | 类似于 $ax^2$ 的导数是 $2ax$,如果是对称矩阵则为 $2Ax$ |
为什么求完导后转置了
这其实是机器学习数学基础中经常让人困惑的**“符号布局”**(Layout Convention)问题。
简单来说,这里之所以是 $A^T$(A的转置),是因为该公式使用了分母布局 (Denominator Layout)。
我来为你拆解一下:
- 两种流派: 在矩阵微积分中,关于“向量对向量求导”的结果形状,主要有两派观点:
- 分子布局 (Numerator Layout):这是纯数学中更常见的定义(雅可比矩阵)。如果 $y = Ax$,那么 $\frac{\partial y}{\partial x} = A$。
- 分母布局 (Denominator Layout):这是部分机器学习教材(以及你这张图)所采用的。为了让求导后的结果(梯度)与分母变量 $x$ 的维度方向一致(方便后续做梯度下降更新),它定义导数为雅可比矩阵的转置。所以在这里,$\frac{\partial Ax}{\partial x} = A^T$。
- 维度的直观理解:
- 假设 $x$ 是一个 $n \times 1$ 的列向量。
- 为了在更新参数时能够直接进行加减运算(比如 $x_{new} = x_{old} - \text{gradient}$),我们希望导数(梯度)的形状也是 $n \times 1$。
- 标准的 $A$ 形状通常是 $m \times n$,而 $A^T$ 的形状是 $n \times m$(如果这里 $Ax$ 被视为标量场的梯度源,情况会更吻合;或者在特定上下文中 $A$ 被视为行向量)。
一句话总结: 这只是定义的“方言”不同。你看到的这个公式是为了让结果的形状更符合工程应用(与 $x$ 的维度对齐),所以加了转置。
对$x^T$求导与对x求导有什么区别
1. 本质上的区别
- 对 $x$ 求导(对列向量求导):
- 你的自变量是竖着的。
- 为了保持兼容,我们通常希望结果也是竖着的(或者在某些布局下与 $x$ 的维度对应)。
- 对 $x^T$ 求导(对行向量求导):
- 你的自变量是横着的。
- 结果通常就会横过来,或者矩阵的维度会发生转置。
2. 具体到 $f(x) = Ax$
假设 $x$ 是 $n \times 1$(列),$A$ 是 $m \times n$,$f(x)$ 是 $m \times 1$(列)。
我们来看看两种求导的区别(这取决于你使用的“方言”,即布局习惯,这里以最通用的雅可比矩阵逻辑为例):
| 求导方式 | 结果形状 | 结果公式 | 解释 |
|---|---|---|---|
| $\frac{\partial (Ax)}{\partial x^T}$ | $m \times n$ | $A$ | 这就是标准的雅可比矩阵。因为 $x^T$ 是横向的($1 \times n$),结果展开就很自然地是一个 $m \times n$ 的矩阵 $A$。 |
| $\frac{\partial (Ax)}{\partial x}$ | $n \times m$ | $A^T$ | (在机器学习常用的分母布局下) 因为 $x$ 是竖向的,为了跟 $x$ 对齐,我们把结果转置了一下,变成了 $A^T$。 |
简单记忆法:
- 对 $x^T$ 求导 $\to$ 结果就是 $A$(原样)。
- 对 $x$ 求导 $\to$ 结果通常是 $A^T$(为了配合分母布局)。
3. 为什么我们在 ML 里很少对 $x^T$ 求导?
因为在编写代码(如 PyTorch 或 TensorFlow)时,我们的参数(比如权重 $w$ 或输入 $x$)通常都是存储为张量(Tensor)或列向量形式。
我们需要计算出的梯度(Gradient)必须能直接加到原参数上。
- 原参数 $x$ 是形状 $(n, 1)$。
- 如果你求导得出的梯度形状是 $(1, n)$,电脑就会报错:“维度不匹配,无法相加”。
- 所以我们默认都使用“对 $x$ 求导”的规则,确保梯度的形状也是 $(n, 1)$。
概论
概率与概率密度之间的关系
数学上的严格关系
在处理连续变量时(比如网络层输出的浮点数特征),随机变量取某一个绝对精确值 $x$ 的概率永远是 $0$,即 $P(X=x) = 0$。
要得到真实的概率 $P$(即在函数图像下的面积),必须对概率密度 $p(x)$ 在一个区间 $[a, b]$ 内求定积分:
$$P(a \le X \le b) = \int_{a}^{b} p(x) dx$$
如果你只看一个极其微小的区间 $\Delta x$,那么概率和密度的关系可以近似表示为:
$$P(x \le X \le x + \Delta x) \approx p(x) \Delta x$$
在计算机视觉中,当我们处理图像的潜在特征向量(Latent Vector)时,特征空间是一个连续的高维空间。
- 概率密度 $p(\mathbf{x})$:它表示某一张特定图像的特征 $\mathbf{x}$ 在整个真实图像流形(Manifold)上的“密集程度”。如果 $p(\mathbf{x})$ 很大,说明这种特征的组合在真实数据集中很常见。
- 概率 $P$:由于单张图片在连续空间中对应的绝对概率为 $0$,在实际的生成模型(如 GAN 或扩散模型)中,我们关注的往往是网络生成一张落在某个合理特征“范围(区间)”内的图像的总可能性。